重要概念
倒排索引
将文本内容进行分词,然后将分词结果放到一个表中,表左边存储分词结果,右边存储其id值。在进行分词的时候直接用词遍历这个表,就能直观拿到对应的数据。
Es核心概念
| Relational DB | Elasticsearch |
|---|---|
| 数据库(database) | 索引(indices) |
| 表(tables) | types(7.x版本中已经被废弃) |
| 行(rows) | documents |
| 字段(columns) | fields |
| 表结构 | 映射(mapping) |
数据类型
简单数据类型
文本类型
| 类型 | 说明 |
|---|---|
| keyword | 不支持分词操作,支持聚合操作 |
| text | 支持分词操作,不支持聚合操作。 |
数值类型
| 类型 | 说明 |
|---|---|
| byte | 有符号的8位整数, 范围: [-128 ~ 127] |
| short | 有符号的16位整数, 范围: [-32768 ~ 32767] |
| integer | 有符号的32位整数, 范围: [−231−231 ~ 231231-1] |
| long | 有符号的64位整数, 范围: [−263−263 ~ 263263-1] |
| float | 32位单精度浮点数 |
| double | 64位双精度浮点数 |
| half_float | 16位半精度IEEE 754浮点类型 |
| scaled_float | 缩放类型的的浮点数, 比如price字段只需精确到分, 57.34缩放因子为100, 存储结果为5734 |
日期类型
JSON没有日期数据类型, 所以在ES中, 日期可以是:
- 包含格式化日期的字符串, "2018-10-01", 或"2018/10/01 12:10:30".
- 代表时间毫秒数的长整型数字.
- 代表时间秒数的整数.
https://www.jianshu.com/p/01f489c46c38
范围类型
| 类型 | 范围 |
|---|---|
| integer_range | −231−231 ~ 231−1231−1 |
| long_range | −263−263 ~ 263−1263−1 |
| float_range | 32位单精度浮点型 |
| double_range | 64位双精度浮点型 |
| date_range | 64位整数, 毫秒计时 |
| ip_range | IP值的范围, 支持IPV4和IPV6, 或者这两种同时存在 |
其他类型
①bool:
可以接受表示真、假的字符串或数字:
真值: true, "true", "on", "yes", "1"...
假值: false, "false", "off", "no", "0", ""(空字符串), 0.0, 0
②二进制
(1) doc_values: 该字段是否需要存储到磁盘上, 方便以后用来排序、聚合或脚本查询. 接受true和false(默认);
(2) store: 该字段的值是否要和_source分开存储、检索, 意思是除了_source中, 是否要单独再存储一份. 接受true或false(默认).
复杂数据类型
数组
ES中没有专门的数组类型, 直接使用[]定义即可;
数组中所有的值必须是同一种数据类型, 不支持混合数据类型的数组:
① 字符串数组: ["one", "two"]; ② 整数数组: [1, 2]; ③ 由数组组成的数组: [1, [2, 3]], 等价于[1, 2, 3]; ④ 对象数组: [{"name": "Tom", "age": 20}, {"name": "Jerry", "age": 18}].
注意:
- 动态添加数据时, 数组中第一个值的类型决定整个数组的类型;
- 不支持混合数组类型, 比如[1, "abc"];
- 数组可以包含null值, 空数组[]会被当做missing field —— 没有值的字段.
对象类型
json数据
地理位置
地理点类型用于存储地理位置的经纬度对, 可用于:
- 查找一定范围内的地理点;
- 通过地理位置或相对某个中心点的距离聚合文档;
- 将距离整合到文档的相关性评分中;
- 通过距离对文档进行排序.
思维导图
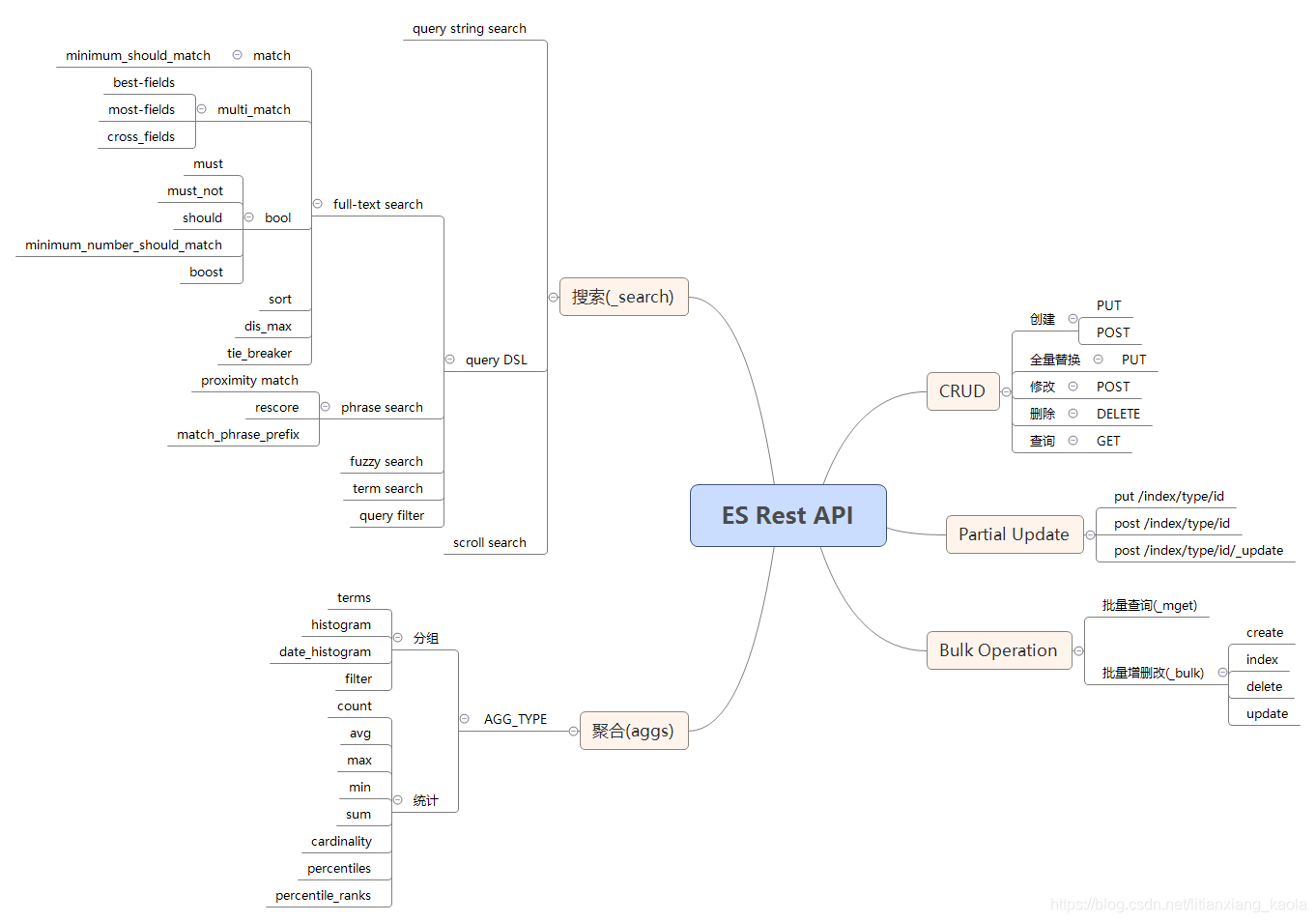
基本使用
es的文件目录中包含:bin(启动文件所在),config(配置文件所在),plugins(插件位置所在)
配置用户
①在config文件夹下修改 elasticsearch.yml,加上配置 ,然后重启es。
xpack.security.enabled: true
②在es的bin目录下,打开CMD输入
elasticsearch-setup-passwords interactive
③会显示响应的提示,根据提示输入自己的密码。
安装插件
bin目录下,CMD输入
# 安装插件
elasticsearch-plugin install [plugin_name]
# URL安装
elasticsearch-plugin install [url]
# 查看es安装的插件
elasticsearch-plugin list
或者,Es安装插件,直接将其丢在es的plugins文件目录下,如将IK分词插件的包解压丢到plugins下,命名为IK.
基础Restful

注意:
更新最好使用 post xxx/_update 这样只会更新对应的数据,而使用put会覆盖掉之前的数据。
DSL查询
match_all
全部查询,配合其他的操作进行数据的筛选,字段的筛选等,并且伴随着条件的增加,建议使用POST方式,
POST /index/_search
{
"query": {
"match_all": {}
}
}
筛选字段
_source对需要的字段进行筛选。
分页
from a size b 拿到目的集合中索引为a到b的数据。
{
"query": {
"match_all": {}
},
"_source": [
"id",
"nickname",
"age"
],
"from": 0,
"size": 10
}
排序
text类型无法排序,keyword类型可以,对于text,可以用它的.keyword进行排序,
"sort": [
{
"age": "asc"
},
{
"money": "desc"
}
]
must
需要满足条件列表中的所有
term/terms
不进行分词搜索,仅仅支持一个字段的筛选,筛选出包含该字符的数据。
term精确匹配,不会进行分词。
terms则表示根据一个列表进行匹配。
对于text文本的信息,能够进行分词,则使用包含搜索信息分词的就能被成功筛选。
然而text类型也有个keyword,不支持分词,其值也text文本内容,用keyword需要全量输入搜索信息才能被成功删选。
参考:https://blog.csdn.net/dg19971024/article/details/107103201
{
"query": {
"terms":{
"name1":"霸王别姬"
}
"terms": {
"name1.keyword": ["霸王别姬","肖申克的救赎"]
}
}
}
match
在查询时,是进行了分词的操作。查询包含某字符分词结果数据的信息。查询也有正则和前缀查询到时候搜。
对于查询的时候,如果是text类型,也可以使用它的.keyword进行相关查询,具体情况具体分析。
例如:我是你爸爸,被分词为 我,是,你,爸爸,筛选结果会是包含其分词结果的数据(具体条件可以定义)。
{
"query": {
"match": {
"name1": {
"query": "我是你爸爸",
"boost": 2
}
}
}
}
具体条件约束
| 名词 | 选择 | 说明 |
|---|---|---|
| operator | "or"/"and" | 如我爱你,被分词我,爱,你,那么or的话含有任意一个分词就行,and则是需要都包含 |
| minimum_should_match | 一个百分数percent | 目标字符串被分为n个词,筛选出出来的数据会包含n*percent个字符 |
| boost | 权重,不设置为1,提高权重设大于1的整数。 |
multi_match
多字段匹配,可以在每个字段后面添加^n,指定权重。各个字段也可以使用*代替前缀或者后缀。
POST /movie/_search
{
"query": {
"multi_match": {
"query": "我是你爸爸",
"fields": [
"name1^2",
"*_content"
],
"type": "cross_fields"
}
}
}
参数
type
打分机制
| 值 | 说明 |
|---|---|
| best_fields | 按照match检索,所有字段单独计算得分并取最高分的field为最终_score,虽然是默认值,但不建议使用,数据量上来后查询性能会下降 |
| most_fields | 按照match检索,融合所有field得分为最终_score |
| cross_fields | 将fields中的所有字段融合成一个大字段进行match检索,此时要求所有字段使用相同分析器 |
| Phrase | 按照match_phrase检索,默认slop为0,执行短语精确匹配,所以即便设置 minimum_should_match 也无效; 取最高字段得分 |
| phrase_prefix | 按照match_phrase_prefix检索,滑动步长slop默认为0;取最高字段得分 |
| bool_prefix | 按照match_bool_prefix检索 |
tie_breaker
取值范围0-1,当type使用默认值 best_fields ,tie_breaker将会改变默认_score计算方式,采用best_field_score + tie_breaker*other_field_score。
analyzer
用户搜索输入词采用哪种解析器进行分词,默认使用mapping阶段指定的分词器;如果analyzer设置和索引阶段的分词器不一致时,且operator为and 那么在执行查询时可能理应完全匹配的短语结果检索为空的情况。
fuzziness
指定模糊程度,支持数字或auto
prefix_length
当使用模糊查询时,用来指定前缀不变长度
lenient
当查询报错时是否忽略该文档,默认为false
operator
匹配关系的逻辑判断,默认为or,当为and时表示所有输入词必须完全匹配
minimum_should_match
该参数生效的前提是operator为or,支持数字、百分比或者混合配置,
zero_terms_query
当用户输入词全部为停用词时是否返回文档,默认为none即不返回数据,设置为all时,查询将被改写为match_all
auto_generate_synonyms_phrase_query
是否开启同义词查询,默认为true
组合查询
must
是指要同时满足多个条件
should
满足一个条件就行。
must_not
都不满足。
filter
四者可以同时使用,里面都是方term/match
{
"query": {
"bool": {
"must": [
{
"match": {
"desc": "大学"
}
}
],
"must_not": [
{
"term": {
"sex": "1"
}
}
],
"should": [
{
"range": {
"age": {
"gt": "18",
"lt": "22"
}
}
},
{
"match": {
"desc": "毕业"
}
}
]
}
}
}
过滤查询
进行范围筛选
{
"query": {
"match": {
"desc": "大学"
}
},
"post_filter": {
"range": {
"money": {
"gt": 100,
"lt": 1000
}
}
}
}
高亮
将目标字符创高亮
{
"query": {
"match": {
"desc": "沙僧"
}
},
"highlight": {
"pre_tags": [
"<span>"
],
"post_tags": [
"</span>"
],
"fields": {
"desc": {}
}
}
}
聚合查询
基本概念
Elasticsearch 的聚合(Aggregations)功能也十分强大,允许在数据上做复杂的分析统计。Elasticsearch 提供的聚合分析功能主要有指标聚合(metrics aggregations)、桶聚合(bucket aggregations)、管道聚合(pipeline aggregations)和矩阵聚合(matrix aggregations)四大类,管道聚合和矩阵聚合官方说明是在试验阶段,后期会完全更改或者移除,这里不再对管道聚合和矩阵聚合进行讲解。
参考:https://learnku.com/docs/elasticsearch73/7.3/5.1.5/6892
基本格式
"aggs" : { <!-- 最外层的聚合键,也可以缩写为 aggs -->
"<aggregation_name>" : { <!-- 聚合的自定义名字 -->
"<aggregation_type>" : { <!-- 聚合的类型,指标相关的,如 max、min、avg、sum,桶相关的 terms、filter 等 -->
<aggregation_body> <!-- 聚合体:对哪些字段进行聚合,可以取字段的值,也可以是脚本计算的结果 -->
}
[,"meta" : { [<meta_data_body>] } ]? <!-- 元 -->
[,"aggregations" : { [<sub_aggregation>]+ } ]? <!-- 在聚合里面在定义子聚合 -->
}
[,"<aggregation_name_2>" : { ... } ]* <!-- 聚合的自定义名字 2 -->
}
指标聚合
得到某个数据的最大,最小,平均值以及方差,平方差,标准差等。
最大(max)/最小(min)/平均(avg)/求和(sum)/计数(value_count)/去重计数(cardinality)
状态(stats)/更多状态(extended_stats)
如果缺损的值,可以设置 "missing": 10
百分比(percentiles)
会列出在某个百分比的数值,例如存的是1到100,5%就是5
percentile_ranks
某个数在某个范围之内,例如1到100,输入的为50,就返回50%,说明50%的在50以内。
在某一个具体的聚合下面可以通过_value获得聚合的值然后做一些运算啥的。
例子
POST /student/_search
{
"query": {
"match_all": {}
},
"aggs": {
"avg_age": {
"avg": {
"field": "age"
}
},
"max_age": {
"max": {
"field": "age"
}
},
"sum_age" : {
"sum" : { "field" : "age" }
},
"min_age": {
"min": {
"field": "age",
"script": {
"source": "_value * 2.0"
}
}
},
"doc_count" : {
"value_count" : { "field" : "age" }
},
"disinct" : {
"cardinality" : { "field" : "age" }
},
"age_stats" : {
"stats" : { "field" : "age" }
},
"more_stats" : {
"extended_stats" : { "field" : "age" }
},
"per" : {
"percentiles" : {
"field" : "age"
}
}
}
}
桶聚合
bucket 可以理解为一个桶,它会遍历文档中的内容,凡是符合某一要求的就放入一个桶中,分桶相当于 SQL 中的 group by。从另外一个角度,可以将指标聚合看成单桶聚合,即把所有文档放到一个桶中,而桶聚合是多桶型聚合,它根据相应的条件进行分组。
桶聚合种类
| 种类 | 描述/场景 |
|---|---|
| 词项聚合(Terms Aggregation) | 用于分组聚合,让用户得知文档中每个词项的频率,它返回每个词项出现的次数。 |
| 差异词项聚合(Significant Terms Aggregation) | 它会返回某个词项在整个索引中和在查询结果中的词频差异,这有助于我们发现搜索场景中有意义的词。 |
| 过滤器聚合(Filter Aggregation) | 指定过滤器匹配的所有文档到单个桶(bucket),通常这将用于将当前聚合上下文缩小到一组特定的文档。 |
| 多过滤器聚合(Filters Aggregation) | 指定多个过滤器匹配所有文档到多个桶(bucket)。 |
| 范围聚合(Range Aggregation) | 范围聚合,用于反映数据的分布情况。 |
| 日期范围聚合(Date Range Aggregation) | 专门用于日期类型的范围聚合。 |
| IP 范围聚合(IP Range Aggregation) | 用于对 IP 类型数据范围聚合。 |
| 直方图聚合(Histogram Aggregation) | 可能是数值,或者日期型,和范围聚集类似。 |
| 时间直方图聚合(Date Histogram Aggregation) | 时间直方图聚合,常用于按照日期对文档进行统计并绘制条形图。 |
| 空值聚合(Missing Aggregation) | 空值聚合,可以把文档集中所有缺失字段的文档分到一个桶中。 |
| 地理点范围聚合(Geo Distance Aggregation) | 用于对地理点(geo point)做范围统计。 |
查询见:
https://learnku.com/docs/elasticsearch73/7.3/5113-sum-aggregation/7321
Es修改
Es中是不允许修改mapping的,但是呢可以通过建立新的索引,然后将原来的数据导入到新的索引中,然后给新的索引去一个别名(删除原来的索引,不需要修改业务代码)。
POST _reindex
{
"conflicts": "proceed",//发生冲突继续执行
"source": {
"index": "old",
"type": "_doc",
"size": 5000, //设置每批迁移的文档记录数
"_source": ["user", "_doc"], //可设置要迁移的索引字段,不设置则默认所有字段
"query": { //可设置要迁移的文档记录过滤条件
"match_all": { }
}
},
"dest": {
"index": "new",
"type": "_doc",
"version_type": "internal" //"internal"或者不设置,则Elasticsearch强制性的将文档转储到目标中,覆盖具有相同类型和ID的任何内容
}
}
# 取别名
POST /index1/_alias/index1_alias
Es集群/分布式
集群:高可用 分担请求压力。
分布式:分担存储压力,解耦。
一些实例
# 统计数据
POST /logs/_search
{
"query": {
"bool": {
"filter": [
{
"term": {
"code": {
"value": "200"
}
}
}
,
{
"range": {
"time": {
"lt": "2022-01-26T15:07:27"
}
}
}
]
}
},
"size": 0,
"aggs" : {
"sales_over_time" : {
"date_histogram" : {
"field" : "time",
"format":"yyyy-MM-dd-HH",
"calendar_interval" : "1h",
"min_doc_count": 0,
"extended_bounds": {
"min": "2022-01-25-00",
"max": "2022-01-30-01"
}
}
}
}
}