Linux
| 命令 | 释义 |
|---|---|
| ifconfig | 查看网络信息 |
| ping ip | 查看是否能互通 |
| homenamectl set-hostname xxx | 修改主机名,方便记忆连接 |
| vim /etc/hosts | 添加ip host的键值对 |
| systemctl start/stop/restart 服务名 | 操作进程 |
| systemctl enable/disable 服务名 | 启用/禁用 |
| shotdown (-c) | 关机(-c 取消关机) |
| sync | 将数据同步到硬盘 |
| reboot | 重启 |
| poweroff | 关机 |
| man xxx | 解释xxx的用法,空格翻页 |
| help xxx | 解释xxx(内部命令)的用法,空格翻页 |
| xx --help | 外部命令 |
| unique | 去重 |
常用快捷键
| 命令 | 释义 |
|---|---|
| ctrl+l | 清屏 |
| ctrl+c | 退出 |
| ctrl+a | 光标移到行首 |
| ctrl+e | 光标移动到行尾 |
| ctrl+r | 搜索历史命令 |
文件操作
| 命令 | 释义 |
|---|---|
| pwd | 打印当前工作目录 |
| cd path | 切换工作目录 |
| .. | 当前目录的上一层 |
| cd - | 返回上一次切换工作目录前工作目录 |
| ls (-a -l) | 查看当前文件夹下东西,-a 全部, -l列出用户权限 |
| ll | 通 ls -l |
| mkdir a b | 创建文件夹a,b |
| mkdir -p /a/b/c | 创建/a/b/c |
| rmdir a b | 删除文件夹a b |
| rmdir -p /a/b/c | 删除c,b如果为空,也删除b,a若为控,也删除a |
| touch xxx | 创建文件 |
| cp source des | 将源文件复制到目的文件夹下(des为路径,前面写\cp为直接覆盖,-r) |
| cp -r sourc des | 递归复制source下所有文件到des |
| rm -rf file/dir | 删除文件或者文件夹,-r递归 -f强制 |
| mv file dir/file | 后者为dir的时候是移动文件,是file的是重命名+移动 |
| cat -n file | 查看文件内容,-n显示行号 |
| more file | 分页显示文件(space 下一页 q退出=输出当前行号) |
| less file | 分页显示文件(space 下一页 /xxx 搜索字符同vim q退出less) |
| > file | 将前面得到的内容输出到file中(覆盖写) |
| >> file | 将前面得到的内容追加到file中 |
| head -n file | 查看文件的前多少行 |
| tail -f file | 滚动查看日志(ctrl s 暂停 ctrl q继续 ctrl c 退出) |
| tail -n file | 查看日志尾部n行 |
| ln -s 源文件 软链接名称 | 软链接(删除软链接同删除文件) |
| history | 查看输入命令历史 |
时间操作
| 命令 | 说明 |
|---|---|
| date | 查看时间 |
| nptdate ip | 设置同步时间服务器 |
详见:https://www.runoob.com/linux/linux-comm-date.html
用户体系
Linux中的用户体系,涉及用户名称,用户所在的组(一个用户有一个主组,也可以有很多副组),当一般用户要使用root的某些权限的时候,可以使用sudo,需要对这个具体要求详细见
https://www.cnblogs.com/yanling-coder/p/10947157.html
用户与组
| 命令 | 说明 |
|---|---|
| useradd 用户名 | 添加用户,添加了一个用户,也会添加一个域用户名同名的组 |
| userdel 用户名 | 删除用户 |
| passwd username | 配置用户密码 |
| groupadd 组名 | 添加组 |
| groupdel 组名 | 删除组 |
| groupmod -n new old | 修改组名 |
| groups | 查看当前用户的组 |
| groups 用户名 | 查看某个用户的组 |
| usermod -g 组名 用户名 | 修改用户的主组 |
| usermod -G 组名 用户名 | 修改用户的副组 |
| id username | 查看用户信息 |
| su username | 切换用户 |
| whoami | 当前用户信息 |
权限
一个文件的权限,有3个rwx,r读,w写,x执行,三个rwx分别指 所属用户权限 所属组的权限 其他组的权限。
对于文件和文件夹的rwx的含义是有差异的。
文件
r 读 w 写(但是不代表能删除,删除涉及文件夹的权限) x能执行
一个用户创建一个文件默认权限为rw-rw-r--
文件夹
r读 w允许在文件夹修改删除增加等操作 x可以进入该文件夹
一个用户创建一个文件夹默认权限为rwxrwxr-x
命令
| 命令 | 释义 |
|---|---|
| chown username file | 更改所有者 |
| chmod xxx file | 修改文件权限( rwx 中有或无分别对应 1 0,即可转换为十进制的0 1 2 3 4 5 6 7) |
| chmod ugoa +-= rwx file | 修改权限(ugo对应用户,用户组。其他组,a即是全部,+-=则是修改权限,rwx修改啥权限) |
| find dir/ -name filename | 查找文件 |
| updatedb | linux中一个存储文件位置的db,更新它 |
| locate filenam | 查找文件位置 |
| | | 管道,将前面命令的输入传给后面 |
压缩与解压缩
| 命令 | 释义 |
|---|---|
| gzip file | 只能压缩文件,压缩后删除 |
| gunzip file.zip | 解压缩 |
| zip -r xxx.zip file | 将file压缩为xxx.zip |
| tar -zxvf 压缩包 -C dir | 解压到dir下 |
| tar -zcvf 压缩包名称 file1 file 2 ... | 将file1,file2打包压缩。 |
tar详解:https://www.runoob.com/linux/linux-comm-tar.html
磁盘管理
df
df命令参数功能:检查文件系统的磁盘空间占用情况。可以利用该命令来获取硬盘被占用了多少空间,目前还剩下多少空间等信息。
df [-ahikHTm] [目录或文件名]
选项与参数:
-a :列出所有的文件系统,包括系统特有的 /proc 等文件系统; -k :以 KBytes 的容量显示各文件系统; -m :以 MBytes 的容量显示各文件系统; -h :以人们较易阅读的 GBytes, MBytes, KBytes 等格式自行显示; -H :以 M=1000K 取代 M=1024K 的进位方式; -T :显示文件系统类型, 连同该 partition 的 filesystem 名称 (例如 ext3) 也列出; -i :不用硬盘容量,而以 inode 的数量来显示
du
Linux du命令也是查看使用空间的,但是与df命令不同的是Linux du命令是对文件和目录磁盘使用的空间的查看,还是和df命令有一些区别的,这里介绍Linux du命令。
du [-ahskm] 文件或目录名称
选项与参数:
-a :列出所有的文件与目录容量,因为默认仅统计目录底下的文件量而已。 -h :以人们较易读的容量格式 (G/M) 显示; -s :列出总量而已,而不列出每个各别的目录占用容量; -S :不包括子目录下的总计,与 -s 有点差别。 -k :以 KBytes 列出容量显示; -m :以 MBytes 列出容量显示;
挂载
| 命令 | 释义 |
|---|---|
| lsblk -f | 查看文件挂载情况 |
| mount/umount | 挂载/卸载 |
硬盘分类:https://www.cnblogs.com/LinuxSuDa/p/4513996.html
进程管理
| 命令 | 释义 |
|---|---|
| ps aux | 查看所有进程(占用率) |
| ps -ef | 查看所有进程(父子进程关系) |
| pstree -pu | 查看进程数-p显示pid,u显示user |
| top | 内存占用 |
进程状态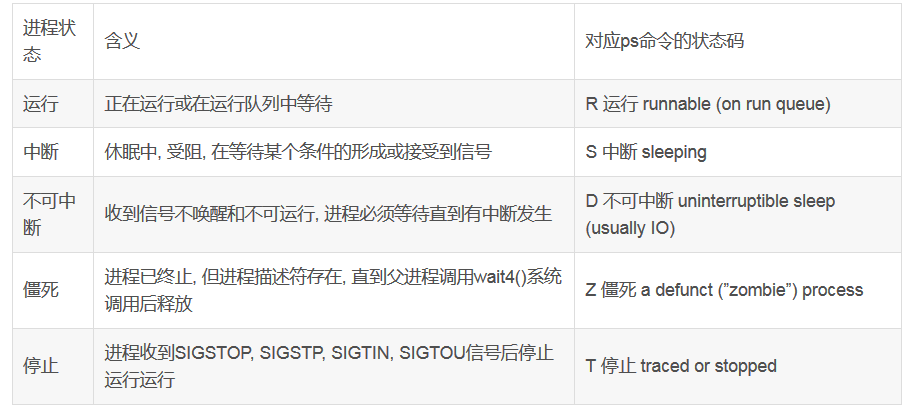
top详解
M 将内存从大到小排序
P按CPU占用从大到小排序,
https://www.jianshu.com/p/8a6754f919c5
网络
netstat -nplt
| 参数 | 释义 |
|---|---|
| -a (all) | 显示所有选项,默认不显示LISTEN相关 |
| -t (tcp) | 仅显示tcp相关选项 |
| -u (udp) | 仅显示udp相关选项 |
| -n | 拒绝显示别名,能显示数字的全部转化成数字 |
| -l | 拒绝显示别名,能显示数字的全部转化成数字 |
| -p | 显示建立相关链接的程序名 |
| -r | 显示路由信息,路由表 |
| -e | 显示扩展信息,例如uid等 |
| -s | 按各个协议进行统计 |
| -c | 每隔一个固定时间,执行该netstat命令 |
软件管理
| 命令 | 释义 |
|---|---|
| apt install xxx | 安装 |
| apt uninstall xxx | 卸载 |
| apt list | 展示列表 |
| apt update xxx | 更新 |
shell
#!/bin/bash
注释
# 仅仅只有单行注释
执行方式
# 如当前文件夹有hello.sh
sh/bash ./hello.sh
./hello.sh
source/. hello.sh
#前两种是在当前用户的bash进程中多开了子进程
#最后一种是单独开了bash的进程
变量
类型
字符
字符串是shell编程中最常用最有用的数据类型(除了数字和字符串,也没啥其它类型好用了),字符串可以用单引号,也可以用双引号,也可以不用引号。单双引号的区别跟PHP类似。
data="this is str"
# ${#str}获取长度
echo ${#data}
# ${str:start:end}截取字符串
echo ${data:1:4}
单引号
- 单引号里的任何字符都会原样输出,单引号字符串中的变量是无效的;
- 单引号字串中不能出现单引号(对单引号使用转义符后也不行)
双引号
- 双引号里可以有变量
- 双引号里可以出现转义字符
数组
bash支持一维数组(不支持多维数组),并且没有限定数组的大小。类似与C语言,数组元素的下标由0开始编号。获取数组中的元素要利用下标,下标可以是整数或算术表达式,其值应大于或等于0。
# 定义
arr=(a b c)
# 使用
echo ${arr[0]}
# 获取所有
${arr[*]}
${arr[@]}
# 取得数组元素的个数
length=${#array_name[@]}
length=${#array_name[*]}
# 取得数组单个元素的长度
lengthn=${#array_name[n]}
系统变量
如$PWD $HOME,可以通过env命令查看当前的变量。
自定义变量
# 定义变量,等号两侧不能有空格
a=xxx
# 撤销变量
unset a
# 将变量设置为只读,只读之后不能unset
readonly a
# 使用
echo $a
# 将变量变为全局全局变量,可以在不同的shell脚本中使用
export a
# 在定义类型的时候,默认为字符串类型,如果需要使用数值类型的运算,需要
a = $((249+1))
a =$[249+1]
特殊变量
可以在将命令中的信息传递到shell脚本中执行,这时候就需要参数,$1-9作为参数名,如果是多位的${10},
且如果需要在shell传入变量,需要使用双引号,如"hello $1",如果使用单引号$x不会被认为是传入的变量。
| 变量 | 含义 |
|---|---|
| $0 | 当前脚本的文件名 |
| $n | 传递给脚本或函数的参数。n 是一个数字,表示第几个参数。例如,第一个参数是$1,第二个参数是$2。n大于9,${n} |
| $# | 传递给脚本或函数的参数个数。 |
| $* | 传递给脚本或函数的所有参数。 |
| $@ | 传递给脚本或函数的所有参数。被双引号(" ")包含时,与 $* 稍有不同,下面将会讲到。 |
| $? | 上个命令的退出状态,或函数的返回值。 |
| $$ | 当前Shell进程ID。对于 Shell 脚本,就是这些脚本所在的进程ID。 |
$* 和 $@ 的区别
$* 和 $@ 都表示传递给函数或脚本的所有参数,不被双引号(" ")包含时,都以"$1" "$2" … "$n" 的形式输出所有参数。
但是当它们被双引号(" ")包含时,"$*" 会将所有的参数作为一个整体,以"$1 $2 … $n"的形式输出所有参数;"$@" 会将各个参数分开,以"$1" "$2" … "$n" 的形式输出所有参数。可以将前者认为是各个参数组成的字符串,而后者则是参数组成的列表。
# shell脚本内容
echo "this is $0"
echo "hello $1"
echo "hello $2"
echo "hello $#"
echo "print each param from \"\$*\""
for var in "$*"
do
echo "$var"
done
echo "print each param from \"\$@\""
for var in "$@"
do
echo "$var"
done
# shell执行命令
./hello.sh xiaobai shell
# 结果
this is 2
hello xiaobai
hello shell
print each param from "$*"
xiaobai shell
print each param from "$@"
xiaobai
shell
变量替换
如果表达式中包含特殊字符,Shell 将会进行替换。例如,在双引号中使用变量就是一种替换,转义字符也是一种替换。
| 形式 | 说明 |
|---|---|
| ${var} | 变量本来的值 |
| ${var:-word} | 如果变量 var 为空或已被删除(unset),那么返回 word,但不改变 var 的值。 |
| ${var:=word} | 如果变量 var 为空或已被删除(unset),那么返回 word,并将 var 的值设置为 word。 |
| ${var:?message} | 如果变量 var 为空或已被删除(unset),那么将消息 message 送到标准错误输出,可以用来检测变量 var 是否可以被正常赋值。 若此替换出现在Shell脚本中,那么脚本将停止运行。 |
| ${var:+word} | 如果变量 var 被定义,那么返回 word,但不改变 var 的值 |
运算符
echo $[(5*5)*10]
条件判断
# 形式一二,中括号前后须有空格
test condition
[ condition ]
# 如
a=250
[ a -eq 250]
数值
| 字符 | 释义 |
|---|---|
| -eq | 等于(equal) |
| -ne | 不等于(not equal) |
| -lt | 小于(less than) |
| -le | 小于等于(less equal) |
| -gt | 大于(greater than) |
| -ge | 大于等于(greater equal) |
字符串
字符串之间的比较 ,用等号“=”判断相等;用“!=”判断不等。
文件权限
| 字符 | 释义 |
|---|---|
| -r | 有读的权限(read) |
| -w | 有写的权限(write) |
| -x | 有执行的权限(execute) |
文件类型
| 参数 | 说明 |
|---|---|
| -e 文件名 | 如果文件存在则为真 |
| -r 文件名 | 如果文件存在且可读则为真 |
| -w 文件名 | 如果文件存在且可写则为真 |
| -x 文件名 | 如果文件存在且可执行则为真 |
| -s 文件名 | 如果文件存在且至少有一个字符则为真 |
| -d 文件名 | 如果文件存在且为目录则为真 |
| -f 文件名 | 如果文件存在且为普通文件则为真 |
| -c 文件名 | 如果文件存在且为字符型特殊文件则为真 |
| -b 文件名 | 如果文件存在且为块特殊文件则为真 |
[ -r hello.sh ]
[ -e hello.sh ]
多条件
# 当command1执行成功会执行command2,
# command1执行失败则会执行command3
command1 && command2 || command3
s && echo true || echo false
ls && echo true || echo false
流程控制
分支
if else
if [ condition ]
then
command1
elif [ condition ]
then
command2
else
command3
fi
# -a(and)两个条件同时成立为真
# -o(or)两个条件需要成立一个为真
if [ condition -a / -o condition ]; then
# 示例
sex=male
if [ $sex = male ]
then
echo '男性'
elif [ $sex = female ]
then
echo '女性'
else
echo 'unknow'
case
# 值与某一项匹配,则执行其中某命令,都不满足执行*)中的,每个都需要;;结束
case 值 in
模式1)
command1
command2
command3
;;
模式2)
command1
command2
command3
;;
*)
command1
command2
command3
;;
esac
# 如
sex=male
case $sex in
male)
echo 'male'
;;
female)
echo 'female'
;;
*)
echo 'unknown'
;;
esac
循环
for
数值
for((i=0;i<=100;i++))
do
xxx
done
# 如
sum=0
for ((i=0;i<=100;i++))
do
sum=$[ $sum + $i ]
done
echo $sum
报错Syntax error: Bad for loop variable,解决
https://blog.csdn.net/liuqinglong_along/article/details/52191382
列表
for i in value1 value2 value3
do
echo $i
done
# 如
for loop in 1 2 3 4 5
do
echo "The value is: $loop"
done
PS: {start..end..step}可以快捷获取列表,如{1,100}表示1到100所有数。
while
while [ condition]
do
xxx
done
# 如
sum=0
i=0
while [ $i -le 100 ]
do
sum=$[ $sum + $i ]
i=$[ $i + 1 ]
done
echo $sum
until
until [ condition]
do
xxx
done
# 如
sum=0
i=0
until [ $i -ge 100 ]
do
sum=$[ $sum + $i ]
i=$[ $i + 1 ]
done
echo $sum
读取输入
shell
# -t 等待时间 -p 提示的信息 将输入内容用variable接收
read -t 7 -p "message you wanna send:" variable
echo $variable
函数
基本形式
# 形式1
function function_name {
do something
}
# 形式2
function_name(){
do something
}
#!/bin/bash
function sum()
{
s=0
s=$[$1+$2]
echo "$s"
}
sum $1 $2s
# 参数则使用$1,$2...
系统函数
即是系统的命令
# 略
自定义函数
#!/bin/bash
function sum()
{
s=0
s=$[$1+$2]
echo "$s"
}
sum $1 $2s
cut和三剑客
三剑客 grep 过滤 sed 修改替换文件内容,取行数据 aws 取列数据
cut
cut 的工作就是“剪”,具体的说就是在文件中负责剪切数据用的。cut 命令从文件的每 一行剪切字节、字符和字段并将这些字节、字符和字段输出。
# 基本
cut args filename
参数 | 字符 | 释义 | | :--: | :-----------------------: | | -b | 以字节为单位进行分割。这些字节位置将忽略多字节字符边界,除非也指定了 -n 标志 | | -c | 以字符为单位进行分割。 | | -d | 自定义分隔符,默认为制表符。 | | -f | 与-d一起使用,指定提取第几列。 | | -n | 取消分割多字节字符。仅和 -b 标志一起使用。如果字符的最后一个字节落在由 -b 标志的 List 参数指示的范围之内,该字符将被写出;否则,该字符将被排除 |
# 如举个例子
# test.txt文件内容如下
# dong shen
# guan zhen
# wo wo
# lai lai
# le le
# 将text.txt的内容按行以空格分隔,提取第一列数据
# 如果是取多列数据 -f a,b,c
cat test.txt | cut -d " " -f 1(,2)
dong
guan
wolai
le
ps:在处理多空格时,如果文件里面的某些域是由若干个空格来间隔的,那么用cut就有点麻烦了,因为cut只擅长处理“以一个字符间隔”的文本内容
grep
过滤文本内容 参数 | 字符 | 释义 | | :--: | :-----------------------: | | -E | 支持正则表达式 | | -A | after -An 过滤出目标以及其后n行数据 | | -B | before -Bn 过滤出目标以及其前n行数据 | | -C | context -Cn 过滤出目标以及其前后n行数据 | | -c | count 统计出现次数 | | -n | 显示行号 | | -i | 忽略大小写 | | -w | 精确匹配,仅仅匹配目标 | | -m n | 仅仅匹配前n个 | | -v | 取出不包含目标字符的行 |
cat xxx | grep -wciv str
参考:https://www.w3schools.cn/linux/linux_comm_grep.asp
awk
一个强大的文本分析工具,把文件逐行的读入,以空格为默认分隔符将每行切片,切开 的部分再进行分析处理。
# 基本形式
awk args /pattern/do something
如pattern
/^root 以root开头,
/101/./105/ 范围在101到105,
NR>=1 && NR<=5 第一行到第五行
参数 | 字符 | 释义 | | :--: | :-----------------------: | | -F ':' | 以字符为单位进行分割。 | | -i | 传入自定义变量 |
BEGIN {operation}操作文件前需要执行的操作 END {operation} 完成文件操作后需要执行的操作
awk内置变量 | 字符 | 释义 | | :--: | :-----------------------: | | FILENAME | 文件名称 | | NR | 已经读取的行数 | | NF | 每行数据切割后的数据量 |
# 将test文本以冒号分割,读取文件前输出begin,打印分割出来以root开头的行的第二个 第三个,并且读取完成后输入 end。
awk -F ':' 'BEGIN{print "BEGIN" } /^root/{print "第二个" $2 " 第三个 " $3 "分割的当前行为" NR "当前行被分" NF } END{print "END"} ' test
更多:https://www.cnblogs.com/fawaikuangtu123/p/10008645.html
sed
对文本的增删查改 参数(x代表下面的操作) | 字符 | 释义 | | :--: | :-----------------------: | | nx | 对应第n行执行某个操作 | | /str/x' | 筛选包含有str的行进行操作 | | /str/./str2/x | 筛选出包含范围str到str2的行进行操作 |
操作 | 字符 | 释义 | | :--: | :-----------------------: | |a | 新增。a后面可以接字符串,而这些字符串会在新的一行出现(当前行的下一行) | | c | 取代。c的后面可以接字符串,这些字符串可以取代n1,n2之间的行 | | d | 删除。d的后面一般不接其他东西 | | i | 插入。i的后面可以接字符串,而这些字符串会在新的一行出现(当前行的上一行) | | p | 打印。亦即将某个选择的数据打印出来。通常p会与参数sed -n一起运行 | | s | 取代。可以直接进行取代的工作。通常这个s的动作可以搭配正规表示法。例如1,20s/old/new/g |
ps:在操作前加!就是不进行某操作,如 '4!d' 不删除第4行
# 打印出第二行
sed -n 2p filename
# 打印出一到五行
sed -n 1,5p filename
# 打印出第一行到最后一行
sed -n 1,$p filename
# 打印出包含str1的行
sed -n /str1/p filename
# 将第三行替换为str
sed 3c str filename
# 添加内容
sed 1,3i str
sed 1,3a str
# 替换 一到五行的str1替换为str2,
# 加g就是全部替换
# 不加就是仅仅是替换每行中的第一个str
sed 1,5s#str1#str2#g
# 后向引用,使用正则将前面内容引用
# 然后在后面通过 \1 \2使用
# \1代表第一个()的内容 \2 代表第二个括号里的内容
sed -r 's#(patter1)_(pattern2)#sss \1 \2'